
Introduction
The goal of this article is to act as a reference that can be used aside while digging through the main articles that can be found here.
Part 1 - An Introduction
Part 2 - Authorization Code Flow + PKCE
Part 3 - Client Credentials Flow
Part 4 - Device Authorization Flow
Part 5 - OpenID Connect Flow
I will update this post from time to time whenever I learn new details about the OAuth & OpenID Connect protocol.
Table of Content
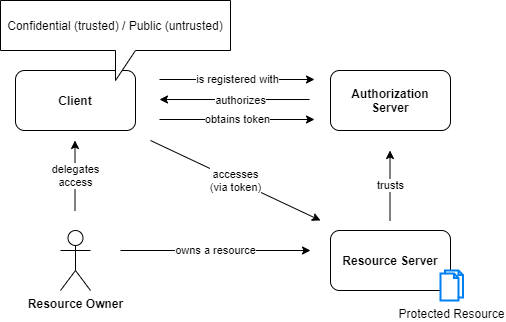
OAuth Actors & Relationship
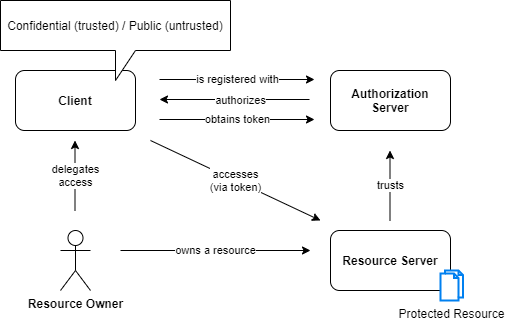
Resource Owner
The resource owner is the person who ownes the data. For example I am the resource owner of my LinkedIn profile or the owner of my google contacts.
This actor is capable of granting or denying access to a protected resource (the data). He only has the power to give a client (application) the privileg to access his data.
In some documentation the resource owner is also called user or end-user, however the resource owner doesn't necessarily have to be a person. I guess that's why RFC 6749 gave this actor the more abstract term resource owner.
Client
The client (sometimes called application) is the actor that wants to access data on behalf of the resource owner and with its authorization.
After the resource owner has given authorization to the client to access the protected data (authorization grant) it provides this grant to the authorization server and gets and access token in exchange. It's this access token that the client later on uses to access the protected resource.
A client is identified by a unique client identifier issued by the authorization server at initial registration time (one time only). This ID needs to be unique to the authorization server, it doesn't require any special protection as it is considered public.
Microsofts Identity Platform uses GUIDs for its client ids, however it's up to the IdP which form of string it uses.
Confidential vs. Public
The RFC 6749 distinguishes between two client types which are called Confidential and Public. The key attribute that distinguishes one from another is it's ability to authenticate securely with the authorization server -- or in other words a confidential client can keep a secret and a public cannot. Now that requires some clarification 😀
When registering a client with the authorization server you get a client identifier and a client password, which are the client (application) credentials. The client identitfier is public wheras the password is a secret and should remain so. This credentials prove the clients identity to the authorization server.
Confidential client
A confidential client is an application running on a server. It's usually written in some of the famous server side languages like .NET, Java, PHP and Node.JS.
A confidential client has the ability to keep strings secret since code is running in a trusted environment. Resource owners access the client via an HTML user interface rendered in a user-agent on the device used by the resource owner.
Public client
A public client in turn can not hold credentials in a secure manner. Examples for public clients are JavaScript applications running in a browser (SPA's), Android or iOS mobile apps, native apps running on a desktop but also applications running on IoT/embedded devices and so on.
This clients are considered public becuase it is technically possible to use debugging tools like Chromes Developer Console or disassemblers to extract confidential information from the binaries/running code.
So any clients executing on the device used by the resource owner, such as an installed native application or a web browser-based application, must be considered public.
Authorization Server
The authorization server is the main engine of OAuth and is sometimes called Identity Provider (IdP), OAuth Server, Token Factory or STS (Secure Token System).
A couple of examples are:
It's this entity who issues access tokens to the client (application) after successfully authenticating the resource owner and obtaining authorization.
An authorization server provides endpoints that fulfill different tasks. They are sometimes called legs.
Authorization Endpoint
The authorization endpoint (RFC 6749, section 3.1) is used by the client to obtain authorization from the resource owner via user-agent redirection.
Token Endpoint
The token endpoint (RFC 6749, section 3.2) is used by the client to exchange an authorization grant for an access token.
Device Authorization Endpoint
This type of endpoint is used by the device authorization flow and got introduced by RFC 8628. It can be used to request device and user codes and is separate from the authorization endpoint with which the user interacts via browser.
Introspection Endpoint
The introspection endpoint provides a mechanism for resource servers to check the validity of access tokens. It's an extension defined in RFC 7662 and can be used to find out information such as which user and which scopes are associated with the token.
Resource Server
This actor is serving the protected resource (e.g. mail contacts). It is capable of accepting and responding to protected resource requests using access tokens. Its also up to the resource server to validate the token. An example for a resource server would be contacts.google.com.
This actor is sometimes refered to API Server or Service Provider (SP).
Please note that the resource server and the authorization server don't necessarily have to be two different systems. Sometimes they are melted together in the same system. But many times they are seperate.
Abstract Flow
The following abstract OAuth 2.0 flow underpins every other flow. This is what it looks like (taken from RFC 6749, Section 1.2).
+--------+ +---------------+
| |--(A)- Authorization Request ->| Resource |
| | | Owner |
| |<-(B)-- Authorization Grant ---| |
| | +---------------+
| |
| | +---------------+
| |--(C)-- Authorization Grant -->| Authorization |
| Client | | Server |
| |<-(D)----- Access Token -------| |
| | +---------------+
| |
| | +---------------+
| |--(E)----- Access Token ------>| Resource |
| | | Server |
| |<-(F)--- Protected Resource ---| |
+--------+ +---------------+
Step A - Authorization Request
The client requests authorization from the resource owner, by asking for consent to access a specific set of resources.
Step B - Authorization Reply
In case the resource owner consents to the authorization request it will return an authorization grant which is a credential representing the given authorization.
Step C - Token Request
The client now requests an access token by authenticating with the authorization server and presenting the authorization grant recieved in the previous step.
Step D - Token Reply
The authentication server authenticates the client and validates the `authorization grant, and if valid, issues an access token.
Step E - Resource Request
The client requests the protected resource from the resource server and authenticates by presenting the access token.
Step F - Resource Reply
The resource server validates the access token, and if valid, returns the requested data.
Authorization Grant
An authorization grant is a credential representing the resource owner's authorization to access its protected resource. Such a grant is used by the client to obtain an access token.
There are four grant types specified in RFC 6749, Section 1.3, which are authorization code, implicit, resource owner password credentials and client credentials. But there are more extension grant types that can be used.
Browser Redirection
The browsers ability to get redirected to another URL is important for several OAuth 2.0 flows to work. This is how a redirect works.
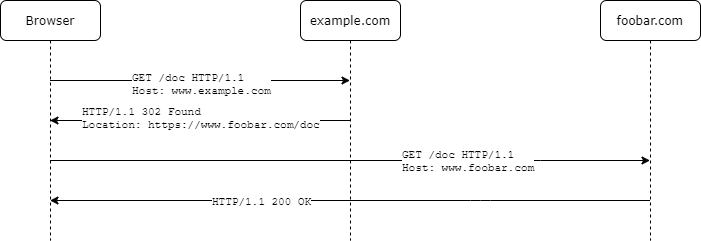
Redirect URI
After completing its interaction with the resource owner, the authorization server directs the resource owner's user agent back to the client. That's where the redirect URI comes into play and tells the browser where to goto next.
This is sometimes called callback or as mentioned in RFC 6749 Section 3.1.2 a redirection endpoint.
Front & Back Channel
Front Channel
A
front-channelcommunication takes place when the communication between two or more parties is observable within the protocol. -- taken from ldapwiki.com
When adopting this academic definition to the OAuth protocol it can be rephrased to:
A
front-channelcommunication takes place, when a request from the authorization server to the client is getting passed via the browser's address bar of the resource owner (via HTTP Redirection).
In the sequence diagram below value is passed from example.com to foobar.com via browser, this communication therefor happens on the front channel.
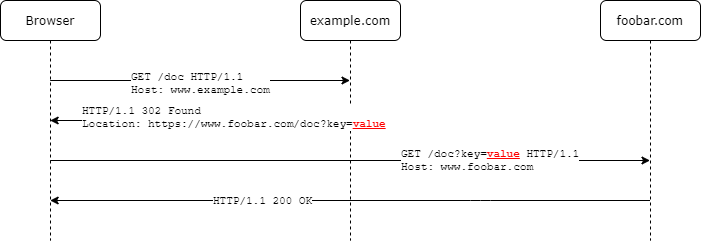
Compared to a back channel communication this is the less secure way to exchange data. It is technically possible that a malicious software (e.g. a browser extension) on the users machine could get hold of it.
However a front channel communication is needed when the protocol requires some user input, which is the case when asking for consent. It shouldn't be used to exchange sensitive information between the actors as we can't trust the browser with secret keys.
Back Channel
A
back-channelcommunication takes place, when the communication is not observable to at least one of the parties within the protocol. -- taken from ldapwiki.com
Rephrasing the above to fit into the OAuth protocol:
A
back-channelcommunication takes place, when data is exchanged between client and authorization server without involving the resource owners machine or browser.
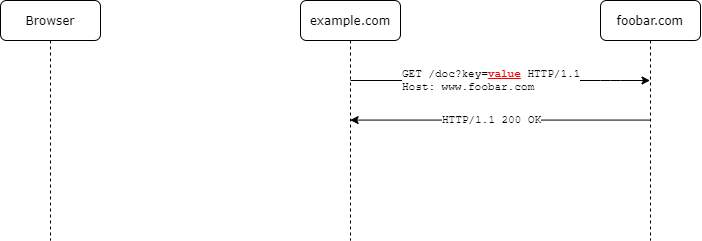
Compared to the front channel communication this is the more secure way to exchange sensitive information between the client and authorization server. As it is always a server to server communication there is no way it can be tampered with from the users side (because the resource owners browser is not involved in it).
Access Token
Tokens are crucial to the OAuth framework. They can be thought of as tags carrying digitally signed information which are getting exchanged between actors.
Usually they take the form of JSON Web Tokens (JWT), but don't have to - according to the specification.
This type of token is a credential used by a client application to access a protected resource. It is a digital representation of the authorization given by the resource owner.
Access tokens are usually used as so called bearer tokens, which means that everyone who gets access to it, can use it! There is no instance, mechanism or whatsoever that checks if a client who uses it, is also the legit owner! It can be compared to cash money. Whoever holds it can use it (this issue got addressed by something called MAC Tokens).
{
"access_token": "2YotnFZFEjr1zCsicMWpAA",
"token_type": "Bearer",
"expires_in": 3600,
"refresh_token": "tGzv3JOkF0XG5Qx2TlKWIA",
}
An access token also carries an expiration date and a scope. Whereas the scope defines what a client is allowed to access. The scope and expiration date is encoded to the access_token and digitally signed.
This is what a decoded token ("access_token":"2YotnFZFEjr1zCsicMWpAA") could look like (exemplarily).
{
"typ": "JWT",
"nonce": "gGoCnX[...]",
"alg": "RS256",
"x5t": "kg2L[...]",
"kid": "kg2L[...]"
}.{
"aud": "https://graph.microsoft.com",
"iss": "https://sts.windows.net/{tenant_id}/",
"iat": 1603730366,
"nbf": 1603730366,
"exp": 1603734266,
"scope": "mail.read"
"aio": "E2RgY[...]",
"app_displayname": "Some Client Application",
"appid": "{client_id}",
"appidacr": "1",
"idp": "https://sts.windows.net/{tenant_id/",
"idtyp": "app",
"oid": "foo",
"rh": "0.AAAATG[...]",
"sub": "foo",
"tenant_region_scope": "EU",
"tid": "{tenand_it}",
"uti": "ejA8[...]",
"ver": "1.0",
"xms_tcdt": 1588704621
}.[Signature]
You won't find a list of scopes in the RFC as the definition of the same is up to the authorization server, whereas an resource server implements them.
For example GitHub defines a scope called
read:user, which allows a client to read a user's profile data.
Access tokens are rather short-lived (minutes or hours), which is a protection measurment that limits it's usage in case someone gets hold of it.
Refresh Token
This type of token is a credential used by the client application to obtain a new access token after it has expired. It is issued to the client application by the authorization server and passed via access token response.
{
"access_token":"2YotnFZFEjr1zCsicMWpAA",
"token_type":"Bearer",
"expires_in":3600,
"refresh_token":"tGzv3JOkF0XG5Qx2TlKWIA",
}
So in case an access token expires the client will authenticate with the authorization server and present the refresh token. The authentication server then validates the refresh token and issues a new access token.
A refresh token can also expire, but is rather long lived and therefor subject to strict storage requirements.
Refresh tokens are getting send only to the authorizations server token endpoint and never to the resource server in contrast to an access token.
Token Validation
In general it's up to the resource server to validate an access token by a corresponding public key (see RSA for more details).
In case the access token is represented as a JWT, the public keys are held in a format called JSON Web Key Set (JWKS). To find the location of that keys, there is usually an OpenID Connect metadata document that carries a jwks_uri element pointing to it.
The metadata document for the Microsoft Identity Platform can be found at this URL https://login.microsoftonline.com/{tenant_id}/v2.0/.well-known/openid-configuration
{
[...]
"jwks_uri": "https://login.microsoftonline.com/{tenant_id}/discovery/v2.0/keys",
[...]
}
To validate a key a resource server doesn't necessarily require a (constant) network connection to the authorization server. This public key can and should be cached.
It is also worth noting, that this relation between the private key, that got used by the authorization server to sign the token, and the public key used by the resource server to validate it, marks the "trust arrow" between both of them.
Authorization Code
A temporary code that is used in the authorization code flow and handed out by the authorization server. This code gets exchanged for an access token in a subsequent step.
The authorization code provides a few important security benefits in the authorization code flow, such as the ability to authenticate the client, as well as the transmission of the access token directly to the client without passing it through the resource owner's user-agent and potentially exposing it to others, including the resource owner (back channel vs. front channel).
It can be seen as a one-time-password and is basically a random string that doesn't encode any data. The specification doesn't prescribe any format the authorization code has to follow (as long as it can passed as a query parameter).


